
Data analysis is the process of examining, cleaning, transforming, and modeling data. Its purpose is to extract valuable information, make predictions, and support decision-making. This systematic approach helps uncover hidden patterns and derive valuable insights from raw data.
This process employs statistical, mathematical, and computational techniques to uncover hidden patterns in data and derive meaningful conclusions.
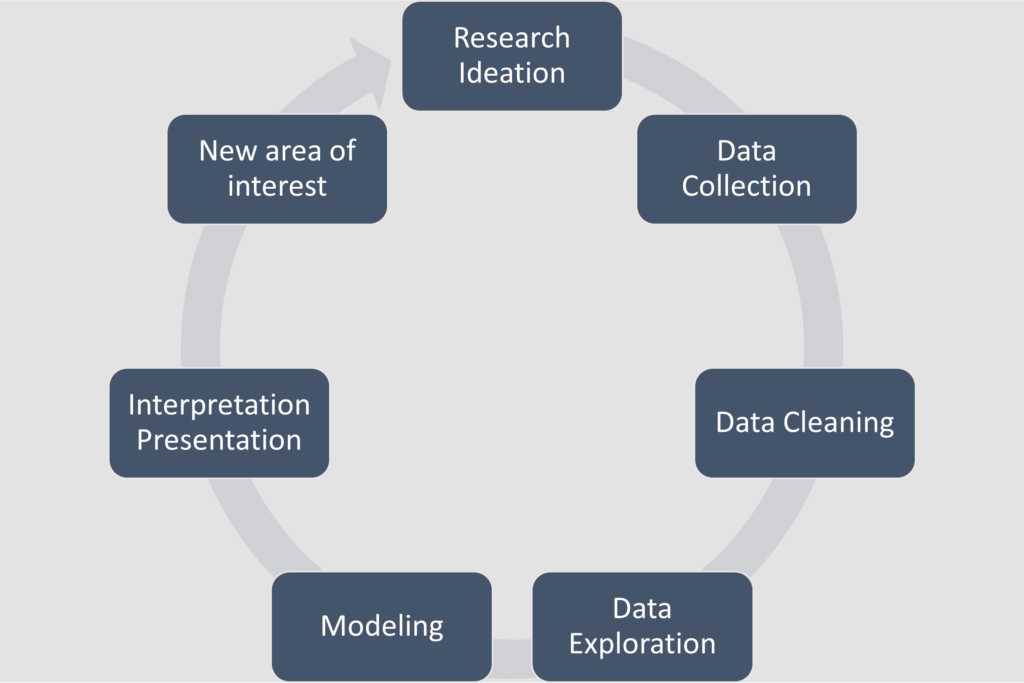
The data analysis process can be broken down into several key steps:
- Data collection: gather comprehensive data from diverse sources including relational databases, NoSQL databases, CSV files, JSON files, web scraping, APIs, sensor networks, and IoT devices. Ensure data variety to capture a holistic view of the subject matter.
- Data cleaning: identify and address data quality issues such as missing values, outliers, inconsistencies, and duplicates. Implement data validation techniques, standardize formats, and document all cleaning procedures to maintain data integrity and reproducibility.
- Data exploration: conduct thorough exploratory data analysis (EDA) using a combination of statistical methods and data visualization techniques. Utilize histograms, scatter plots, box plots, and correlation matrices to uncover underlying patterns, distributions, and relationships within the dataset.
- Modeling: develop and apply sophisticated mathematical, statistical, or machine learning models to extract insights from the data. This may involve techniques such as regression analysis, classification algorithms, clustering methods, time series forecasting, or deep learning approaches, depending on the nature of the data and the research objectives.
- Interpretation and presentation: synthesize findings into clear, actionable insights. Create compelling data visualizations, interactive dashboards, and comprehensive reports to effectively communicate results to stakeholders. Contextualize the findings within the broader business or research context, highlighting their practical significance and potential impact.
The data analysis process is inherently iterative and cyclical. It doesn’t conclude with the interpretation and presentation of results; these outcomes serve as a foundation for further investigation. The insights gained from one round of analysis often highlight new areas of interest or reveal previously unnoticed patterns, prompting additional data collection and analysis. This creates a self-perpetuating cycle of inquiry and discovery, where each analytical phase informs and shapes the direction of subsequent investigations. By adopting this circular nature, data analysts can continually refine their understanding, uncover deeper insights, and adapt their approaches to extract maximum value from the data at hand.
In the subsequent pages, we will embark on a comprehensive journey through the various stages of the data analysis process, leveraging the diverse and powerful tools that Python offers. Our exploration will encompass each crucial step, from initial data collection and preprocessing to advanced modeling and visualization techniques. We’ll explore Python’s rich ecosystem of libraries and frameworks, showcasing how they can be effectively utilized to address complex analytical challenges.
