Preparing data for statistical analysis and result interpretation must start with an accurate assessment of data quality and the correction (cleaning) of any identified issues. Reliable, robust, and reproducible results from our analyses require meticulously collected, error-free data.
However, in the real world, achieving this goal is often elusive. Therefore, a crucial and sometimes challenging part of the data analysis process is dedicated to verifying data quality and cleaning.
In the following sections, we’ll first explore the initial database quality control process. Afterward, we will examine the data cleaning techniques in detail, including some mentioned earlier.
The process of assessing data quality is centered on a thorough examination of various key elements. This includes evaluating the completeness of the data to ensure all necessary information is present, checking the accuracy to confirm that the data correctly represents the real-world conditions it stands for, ensuring consistency so that the data remains uniform across different datasets and periods, verifying the validity to ascertain that the data adheres to the defined formats and standards, and examining the uniqueness to identify and eliminate any redundant entries within the dataset.
A comprehensive set of tools employed to assess and verify the quality of data is referred to as Exploratory Data Analysis (EDA). This analytical approach is a cornerstone in understanding the intricacies of datasets.
EDA employs a range of descriptive statistical methodologies, including but not limited to computations of mean, median, standard deviations, percentiles, and range. These statistical techniques are crucial for gaining insights into the distribution patterns of the data.
A significant aspect of EDA is the deployment of diverse graphical visualization techniques. These visual tools are utilized to meticulously evaluate the distribution characteristics of the data and explore the various interrelationships within the dataset.
In the following example, a fictitious database will be created, and typical EDA descriptive statistical and graphical techniques will be applied.
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# Example dataset
data = {
'Age': [25, 30, 22, 40, 28, 35, 45, 29, 34, 38],
'Income': [50000, 54000, 50000, 61000, 58000, 57000, 80000, 52000, 59000, 62000]
}
df = pd.DataFrame(data)
# Descriptive statistics
print("\nDescriptive Statistics:")
print(df.describe())
# Histogram
plt.hist(df['Age'], bins=5)
plt.title('Age Distribution')
plt.show()
# Scatter plot
sns.scatterplot(x='Age', y='Income', data=df)
plt.title('Scatter Plot of Age vs. Income')
plt.show()
Checking for missing data is another key element in assessing data quality.
In Python, this can easily be done using .isnull()sum().
# Example dataset with missing values
data = {'A': [1, 2, None, 4], 'B': [None, 2, 3, None], 'C': [1, 2, 3, 4]}
df = pd.DataFrame(data)
# Count missing values
print("\nMissing Values Count:")
print(df.isnull().sum())
Another crucial analysis involves searching for outliers—anomalous values significantly deviating from the normal data distribution. This can be done using graphical methods (box plots), statistical methods (Z scores), or quartile-based approaches.
An essential check in the process of data analysis is the assurance of consistency: the values of variables must remain coherent and logical throughout. This task involves conducting both cross-checks—such as making a comparison between the age field and employment status to detect any inconsistencies that may arise between extreme ages and active employment—and verifying the adherence to integrity rules, such as ensuring that a sale price cannot possibly be negative.
It is of utmost importance to confirm that data entries are within the anticipated and permissible range, which is known as a domain check. For instance, a field dedicated to recording gender should strictly accommodate only two possible variables, namely “M” for male and “F” for female. Similarly, an age-related field must logically exclude any negative values as they are not feasible. Furthermore, when dealing with a field that is intended to store date entries, it is essential to ensure that all dates conform to a consistent format. Additionally, in certain situations, particularly those involving text fields, regular expressions (RegEx) prove to be effective tools for verifying the accuracy of specific data, such as validating the structure of an email address or confirming the format of a phone number.
It is essential to verify that all the values recorded in the dataset are unique and to ensure that there are no duplicate entries. In Python, utilizing the duplicate() function can be particularly helpful in identifying and addressing these issues.
The examination of data distribution can be accomplished through a variety of statistical and graphical techniques. This analysis is not only crucial but also instrumental in determining the appropriate type of statistical analysis to be conducted subsequently.
Moreover, detecting and correcting any typographical or semantic errors within the dataset is crucial. Although this process is challenging and labor-intensive, it can be enhanced by using specialized techniques such as normalization and algorithms like fuzzy matching to improve accuracy and efficiency.
In conclusion, the process of examining correlations between various data points is significant as it enables us to not only establish and understand the relationships that exist between these data elements but also to identify any erroneous data that may be present. In certain instances, these correlations can be detrimental to statistical analysis, especially if they reveal a phenomenon such as multicollinearity, wherein multiple variables are interrelated in such a way that they complicate the analysis.
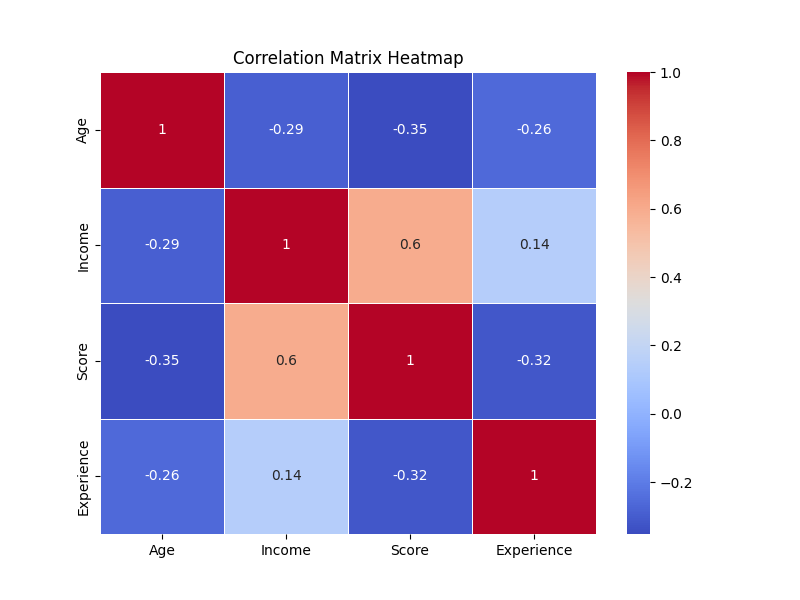
The examination of correlations can be effectively conducted through the creation of correlation matrices. These matrices provide a structured approach to understanding relationships. Alternatively, and often more visually impactful, is the construction of graphs like heatmaps. Heatmaps offer a graphical representation that, at first glance, immediately reveals the intricate relationships between different variables, making them a valuable tool for data analysts.
Generate a correlation matrix with Python:
# Correlation matrix
correlation_matrix = df.corr()
print("\nCorrelation Matrix:")
print(correlation_matrix)
In the next example, a simple dataset is created using random number generation from NumPy. Then, we create a correlation matrix (which displays Pearson correlation coefficients) among the different variables using the corr() function from pandas. Finally, we use the heatmap function from seaborn to create a graph where, by applying the “coolwarm” color palette, positively correlated values will be shown in red, negatively correlated ones in blue, and non-correlated ones in white.
# import library
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# Step 1: Create a sample dataset
# Generate a sample dataset with random numbers
np.random.seed(0)
data = {
'Age': np.random.randint(20, 60, 10),
'Income': np.random.randint(30000, 80000, 10),
'Score': np.random.randint(1, 100, 10),
'Experience': np.random.randint(1, 20, 10)
}
df = pd.DataFrame(data)
# Step 2: Compute the correlation matrix
correlation_matrix = df.corr()
# Step 3: Plot the heatmap
plt.figure(figsize=(8, 6)) # Set the size of the heatmap
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', linewidths=0.5)
# Customize the plot
plt.title('Correlation Matrix Heatmap')
plt.show()