
Data cleaning is the crucial phase that follows data collection in the analysis process. It employs various techniques to ensure the data is accurate and consistent for further analysis.
The data cleaning process typically includes these steps:
- Organization of variables
- Data quality assessment
- Handling missing values
- Handling duplicates
- Handling outliers
- Format management
- Normalization and standardization
- Validation
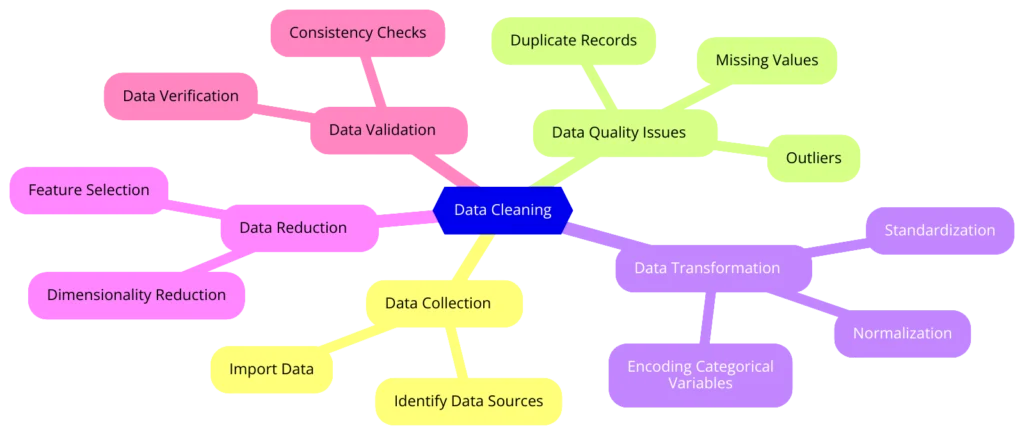
These points will be explored in detail on the subsequent pages.
A critical and often underappreciated aspect of the data cleaning process is the meticulous documentation of all actions. This documentation serves multiple purposes: it ensures transparency, facilitates reproducibility, and allows for tracking changes throughout the cleaning process. Equally important is the preservation of both the original, unaltered dataset and the modified versions produced at each stage of the cleaning process.
This comprehensive approach to data management offers several significant advantages. Firstly, if needed, it allows for the reconstruction of the initial dataset, which can be crucial for verification purposes or if errors are discovered in the cleaning process. Secondly, it enables researchers to perform comparative analyses using different versions of the cleaned data, providing insights into how various cleaning techniques might impact the final results. Lastly, this method supports the principles of open science by allowing other researchers to understand and potentially replicate the data cleaning process, thereby enhancing the overall reliability and credibility of the research findings.

